Case Study — Finger Lakes Daily News
When Pharma Spammers Try to Poison a Local News Site
How we caught and killed an SEO attack that was weaponizing WordPress's own RSS feeds—in a single afternoon.
The Signal
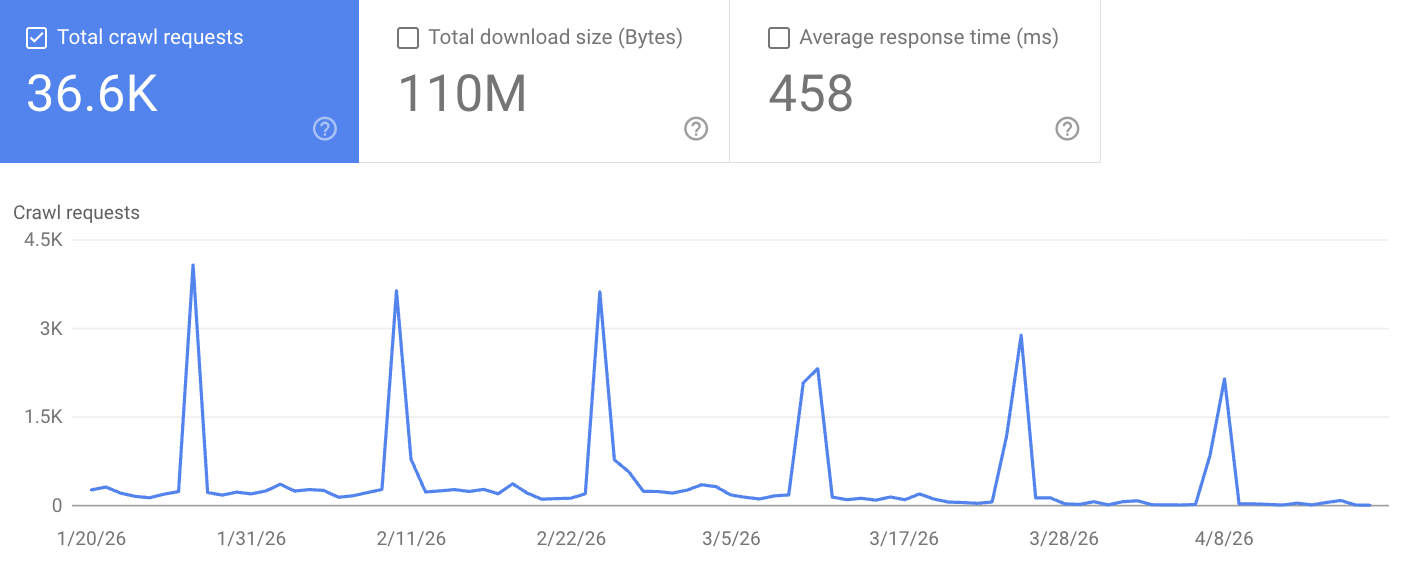
Something Was Telling Google to Come Back for More
Google Search Console's feed-crawler report showed a strange pattern: every two weeks, crawl requests against Finger Lakes Daily News jumped from ~200/day to 2,000–4,000/day, then returned to baseline. Like clockwork—Jan 27, Feb 10, Feb 24, Mar 10, Mar 24, Apr 7. Exactly 14 days apart.
Normal crawl behavior doesn't spike on a calendar. Something was pulling Googlebot back on a schedule.
The Investigation
Three Problems in the URL List — One of Them an Active Attack
We pulled the list of URLs Google's feed crawler was hitting. The pattern was immediately obvious—and it wasn't just one thing going wrong.
/search/<pharma-query>/feed/rss2/. WordPress turns any search query into an indexable RSS feed. Attackers link to those URLs from compromised sites, Google crawls them, and pharmacy spam ends up indexed under our domain./tag/*/feed, /author/…/page/850/feed, /category/local/page/559/feed, and /ad_block/…/feed/—archive pages with no unique content, burning crawl budget that should be going to actual journalism.8216 — the HTML entity number for a left-single-quote (‘). The RSS-import pipeline was slugifying article titles without decoding HTML entities first, generating a trail of broken tag pages Googlebot kept revisiting.The Fix
410 Gone, at the Origin, Before Anything Else Runs
Two commits to the theme's SEO module—roughly 70 lines of PHP. The fix had to neutralize the active attack without breaking the feeds that actual readers and syndication partners depend on.
1. Hard-fail the spam vector
A template_redirect hook at priority -1 intercepts /search/*/feed/, /tag/*/feed/, /author/*/feed/, and deep-pagination archive feeds before WordPress tries to render them. Returns 410 Gone with X-Robots-Tag: noindex, nofollow. 410 is the strongest signal we can send Google: this URL existed, it's gone, stop asking.
2. Seal it off at robots.txt
Five new Disallow: rules covering tag feeds, author feeds, category deep-pagination feeds, the /ad_block/ taxonomy leak, and generic paginated feeds. Belt-and-suspenders: 410 handles already-indexed URLs; robots.txt prevents new crawlers from hitting them in the first place.
Verification
What Changed, What Didn't
Measured on production after CF cache purge. Every URL confirmed with curl -sI.
| URL | Before | After |
|---|---|---|
/search/cialis/feed/rss2/ | 200 OK (served spam) | 410 Gone |
/author/lucas/feed/ | 200 OK | 410 Gone |
/tag/geneva/feed/ | 301 → homepage | 410 Gone |
/category/local/page/559/feed | 200 (deep pagination) | 301 → top-level feed |
/feed/ (home) | 200 | 200 ✓ |
/<slug>/feed/ (single-post comments) | 200 | 200 ✓ |
/news-sitemap.xml | 200 | 200 ✓ |
/local/feed/ (top-level category) | 200 | 200 ✓ |
Why It Matters
This Is Running Against Thousands of Sites Right Now
This kind of attack isn't rare. It's quietly running against thousands of WordPress sites this week. Cheap for attackers—just links from compromised sites, nothing installed, nothing exploited. Expensive for the targets—index pollution, crawl-budget waste, potential manual spam penalties. And invisible unless someone is actually reading their crawl-stats reports.
Local newsrooms don't have a dedicated SEO engineer watching GSC every week. What caught this was the monitoring infrastructure we built out earlier this year: daily crawl-stats ingested into BigQuery, anomaly detection running on the droplet, and an AI assistant reading the report so humans don't have to.
The attackers have 14 days to notice they're being rejected. We have 14 days of clean data coming.